
Monday, October 4th 2021 – Facebook and its family of apps, including Instagram and WhatsApp were inaccessible for hours, disrupting lives and business operations of billions of people worldwide. Even Facebook’s internal communications platform, Workplace, was down, disabling plenty of employees to do their jobs and preventing the team from implementing a quick fix.
What exactly happened?
Facebook’s apps — which include Facebook, Instagram, WhatsApp and Messenger — started displaying error messages around 11:40 a.m. Eastern time, according to users. Within a few minutes, Facebook disappeared from the internet, and the outage lasted over five hours. Facebook eventually restored its service after one of their teams got access to its server computers at a data center in Santa Clara, California, and reset them.
The impact of this outage was catastrophic for billions of people around the world. In some countries, like Sri Lanka, Myanmar and India among others, Facebook is the internet. More than 3.5 billion people around the globe rely on Facebook, Instagram, Messenger and WhatsApp to communicate with friends and family, distribute political messaging, and expand their businesses through advertising and outreach.
In addition, Facebook is used to sign in to other web apps and online services, leaving people unable to log into shopping websites or sign into their smart TVs, thermostats and other internet-connected devices.
What caused the outage?
A gaze at Down Detector shows the problems were widespread. While it’s unclear exactly why Facebook’s apps and platforms were unreachable for its users, Facebook’s DNS records indicate that the issue might be DNS related.
Cloudflare senior vice president Dane Knecht however attributes the issue to Facebook’s border gateway protocol. BGP helps networks select the best possible path to deliver internet traffic. According to Knecht Facebook’s border gateway protocol routes were suddenly “withdrawn from the internet.”
According to Gary Chen, VP of Security Operations at Mlytics at the time of the incident, Facebook, Instagram and Whatsapp’s DNS TTLs were at 3600 seconds. Applications kept on reloading content either in the fore- or background before DNS lookups expired. This possibly generated a vast amount of traffic on the internet, especially throughout the 1st hour of the outage.
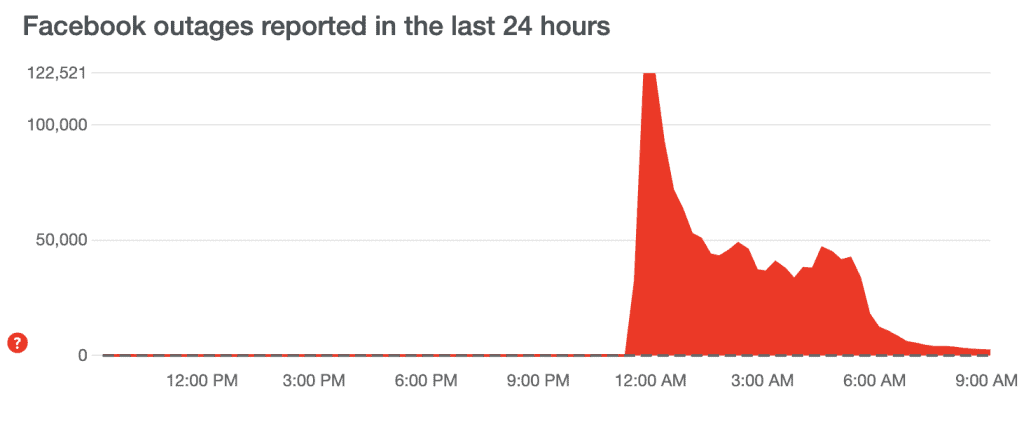
Additionally, Cloudflare DNS query report shows that at the time of the incident DNS resolvers worldwide were handling 30x more queries, directly affecting the latency of CDN providers including Cloudflare and Fastly.
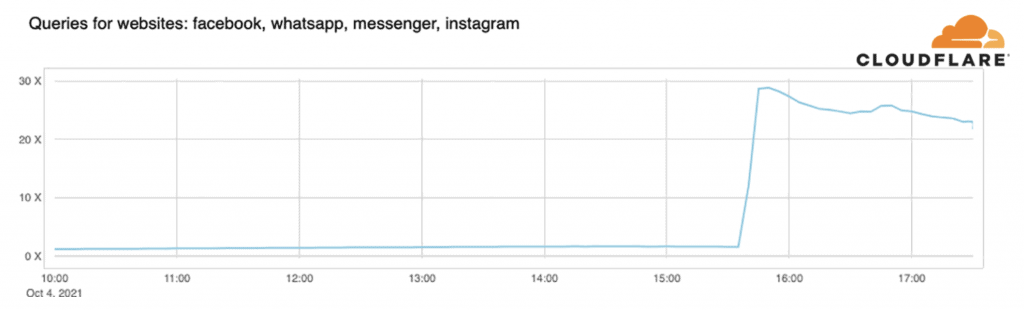
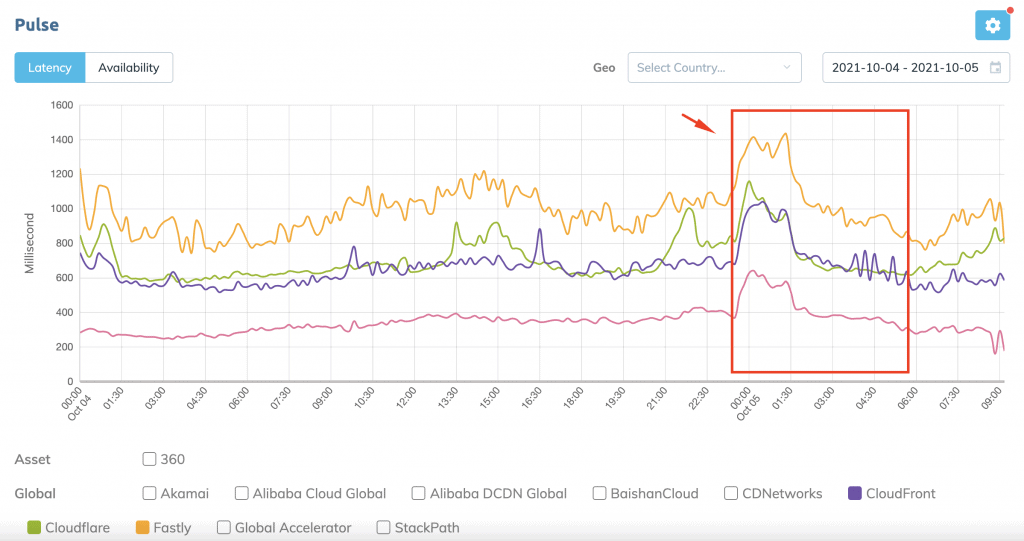
While some have raised concerns about hackers, or an internal protest over the whistleblower testifying before Congress, Facebook stated late Monday that this incident was caused by changes to its underlying internet infrastructure that coordinates the traffic between its data centers. This interrupted communications and cascaded to other data centers, “bringing services to a halt,” the company stated.
What should we take away?
Technology outages and downtimes do happen, but to have so many apps go down from the world’s largest social media company at the same time, especially for such a long period of time, is unusual. Facebook’s last significant outage was in 2019, when a technical error affected its sites for 24 hours. These incidents remind us that the smallest glitch can take down even the most powerful internet companies.
Therefore, it is crucial to have a solid resilience and disaster recovery plan in place to prevent any event from causing your service to go down. In essence, this boils down to relying on multiple infrastructure and service providers, in stead of putting all your eggs in one basket. Opting for a Multi CDN solution is a proactive approach that eliminates the need for reactive ones later.


